
Dans la première partie, nous avons parlé du SSO et de son implémentation via le protocole SAML. Dans cette seconde partie, nous allons voir l’utilisation d’OpenID Connect (OIDC) pour le SSO, mais d’abord, il nous faut comprendre oAuth2 sur lequel se base OIDC.
SAML permet à un utilisateur d’accéder à un Service Provider (SP) qui lui demande de s’authentifier auprès d’un Identity Provider (IdP). Dans ce cas l’utilisateur obtient ses droits (autorisations) sur le SP et accède aux ressources que celui-ci présente.
En revanche, comment faire si ce n’est pas l’utilisateur qui veut accéder à ses ressources dans le Service Provider, mais qu’une autre application veut y accéder à sa place ? Il donne son mot de passe à l’application ? Bien sûr que non. En plus, on voudrait que l’application n’accède qu’à une partie des ressources de cet utilisateur. On voudrait donc pouvoir déléguer finement les autorisations, que l’utilisateur a sur ses ressources, à une application tierce. C’est le problème que résout oAuth2.
Pour rappel, l’authentification est l’acte de déterminer qui s’authentifie pour accéder au service, et l’autorisation est l’acte de déterminer ce qu’il a le droit de faire sur ce service.
I – oAuth2
1 – Terminologie oAuth2
oAuth2 a été standardisé dans plusieurs RFCs (Request For Comments) de l’IETF (Internet Engineering Task Force), en commençant par la RFC 6749.
On va commencer par un peu de terminologie, car il y a pas mal d’éléments qui entrent en jeu dans oAuth2. Vous pouvez y revenir plus tard et commencer par les explications techniques de l’Authorization Code Flow.
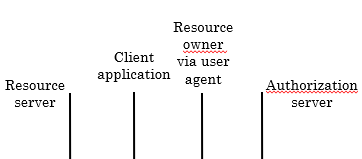
Nous avons ici quatre parties : le resource owner via un user agent, une Client application, un Authorization server, et un Resource server.
- Resource owner : l’utilisateur qui possède les ressources
- User agent : un navigateur web
- Client application : l’application qui veut accéder aux ressources
- Authorization server : le serveur qui donne le token d’accès
- Scope : les ressources auxquelles on veut accéder
- Consent : l’accord de l’utilisateur pour l’accès aux ressources
- Authorization grant : l’élément qui dit au client qu’il a reçu le consent de l’utilisateur et l’autorisation du server
- Authorization flow : souvent synonyme de grant, c’est l’échange qui permet de récupérer un grant puis d’accéder au resource server
- Redirect URI : où le resource owner est redirigé par l’authorization server après le avoir donné le consent
- Code : l’authorization grant qui est donné dans le cas du authorization code flow
- Access token : le token qui contient les informations sur les droits donnés au Client. Au format JWT (JSON Web Token).
- Claims : les droits sur le resource server, attribués par rapport au scope demandé
2 – Flows oAuth2
Voici les flows oAuth2 (échanges entre les parties) que nous allons expliquer techniquement dans le reste de cet article :
- Authorization code flow : le plus utilisé par les web apps qui ont un backend pour communiquer avec l’authorization server.
- Implicit flow : utilisé pour les Single Page Applications et les Native Applications qui n’ont pas de backends et passent par le navigateur pour récupérer l’access token.
Historiquement, les SPA (p.ex. javascript) ne pouvaient pas faire de requêtes à des sites web externes. Aujourd’hui c’est possible avec CORS.
Aussi, les SPA et les NA ne peuvent pas utiliser de Client Secret. - Authorization code flow with PKCE (Proof Key for Code Exchange) : remplace Implicit flow qui n’est plus recommandé. Ce n’est pas un nouveau flow mais ajoute des vérifications à l’authorization code pour le rendre plus sécurisé.
- Client credentials flow : utilisé quand le client demande un access token pour lui-même au lieu de le faire pour un utilisateur.
- Resource owner password credentials flow : l’utilisateur donne au Client ses username/password. Utilisé quand l’utilisateur a grande confiance dans le Client. Mais n’est généralement pas recommandé.
2.1 – Authorization code flow
Ici la Client application veut accéder à des ressources qui appartiennent à l’utilisateur (resource owner) et qui se trouvent sur le resource server. Elle fait passer l’utilisateur par l’authorization server pour qu’il lui délègue ses autorisations sur ces ressources.
2.1.1 – échanges authorization code flow
Voilà ce qui se passe dans l’authorization code flow du début à la fin :

- L’utilisateur accède à l’application Client qui veut avoir accès à des ressources de l’utilisateur (contacts Facebook, channels Slack, repos GitHub)
- Le Client redirige (HTTP 302) vers l’auth server en demandant le scope approprié, et demandant un authorization code
- L’utilisateur s’authentifie sur le server
- Il accepte de donner accès au Client pour le scope
- L’auth server redirige (HTTP 302) l’utilisateur vers la Redirect URI spécifiée par le Client avec un authorization code
- Le Client récupère le code et demande à l’échanger contre un access token
- Le Client reçoit l’access token, au format JWT (JSON Web Token), avec les claims sur le resource server
- Le Client demande l’accès aux ressources en présentant l’access token dans la demande
- Le resource server valide l’access token et donne accès au Client
Pour l’authorization code flow, la Client application passe par le navigateur (user agent) de l’utilisateur pour récupérer le code, c’est ce qu’on appelle le front channel. En revanche pour récupérer l’access token, il consulte directement l’authorization server sans passer par le navigateur de l’utilisateur, c’est ce qu’on appelle le back channel. Celui-ci sert à sécuriser l’échange de l’access token qui ne passe plus par le navigateur, ce qui permet aussi via les client_id et client_secret de la Client application de vérifier que c’est bien celle-ci qui récupère le token.
2.1.2 – Les appels HTTP
Pour que ce soit plus clair, Voici un exemple d’appels et réponses HTTP qui sont réalisés par les différents partis :
- GET /oauth2/authorize
?response_type=code (l’application demande un code)
&client_id=$ClientID (celui de la Client application)
&redirect_uri=https://client-app.com/oauth2/callback\ &scope=resource1 (sur quelle ressource l’application essaye d’avoir les autorisations)
&state=random42 (pour faire correspondre la réponse à cette requête)
HTTP/1.1
Host: auth-server.com
- HTTP/1.1 302 Found
Location: https://client-app.com/oauth2/callback?code=SplxlOBeZQQYbYS6WxSbIA (redirige le navigateur vers le Redirect URI de la Client application avec le code dans le corps du message)
&state=random42 (pour faire correspondre cette réponse à la requête origin)
- POST /oauth2/token
Content-Type: application/x-www-form-urlencoded grant_type=authorization_code (l’application spécifie le type de flow, et qu’elle veut échanger le code contre un token)
&code=SplxlOBeZQQYbYS6WxSbIA (le code reçu lors du dernier échange)&client_id=s6BhdRkqt3 (l’identifiant de la Client application)
&client_secret=7Fjfp0ZBr1KtDRbnfVdmIw (Le secret de la Client application pour s’authentifier auprès de l’auth server)
&redirect_uri=https://client-app.com/oauth2/callback (ne sert que pour vérifier que ça correspond à la Client application)HTTP/1.1
Host: auth-server.com
- HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Cache-Control: no-store
{ “access_token”:“2YotnFZFEjr1zCsicMWpAA…”, (le token au format JWT pour accéder aux ressources)
“token_type”: “bearer”,
“expires_in”:3600,
“refresh_token”:“tGzv3JOkF0XG5Qx2TlKWIA” (un token qui sert à demander de nouveaux access token quand ces derniers ont expirés sans refaire passer l’utilisateur par la case authentification)
}
- GET /resource
Authorization: Bearer 2YotnFZFEjr1zCsicMWpAA… (l’access token qui a été reçu)
HTTP/1.1
Host: resource-server.com
- HTTP/1.1 200 OK
…
2.1.3 – L’anatomie d’un JWT
Un access token au format JSON Web Token se compose de trois partie : le Header, le Body et la Signature. Le Header contient les informations sur le token (type, algorithme de signature), le Body contient les claims (c.f., revoir la définition dans la terminologie oAuth2 plus haut), la Signature contient sans surprise la signature du token par l’Authorization server.
Ici, on peut voir que dans les claims reçus, on peut trouver une informations sur les roles que la Client application a reçus par rapport au scope demandé “resource1” sur le resource server. Ce sont les claims qui vont servir au Resource server pour déterminer ce que la Client application a le droit de faire avec les resources auxquelles elle veut accéder.
Header
{
"typ": "JWT",
"alg": "RS256",
"x5t": "nOo3ZDrODXEK1jKWhXslHR_KXEg",
"kid": "nOo3ZDrODXEK1jKWhXslHR_KXEg"
}
Bod
{
"aud": "https://resource-server.com",
"iss": "https://auth-server.com",
"iat": 1612968229,
"nbf": 1612968229,
"exp": 1612972129,
"appid": "41793faa-3224-42a6-95dd-04ac5cdddddd",
"idp": https://auth-server.com",
"rh": "0.DSAAvLurRwWxfUOaXx05U9yUT6o_eUEkMqZCld0ErFxTNt0gAAA.",
"roles": [
"Myrole"
],
"sub": "9b86897b-265e-4c46-8b6f-835d50c62497",
"tid": "47abbbbc-b105-437d-9a5f-1d3953dc944f",
}
Signature
{
Signature
}2.2 – Implicit flow
Comme décrit plus haut, l’Implicit flow sert aux applications qui n’ont pas de possibilité d’appeler elles-mêmes l’authorization server pour échanger un code contre un access token. Elles demandent alors directement l’access token via le navigateur de l’utilisateur.
2.1.1 – échanges implicit flow
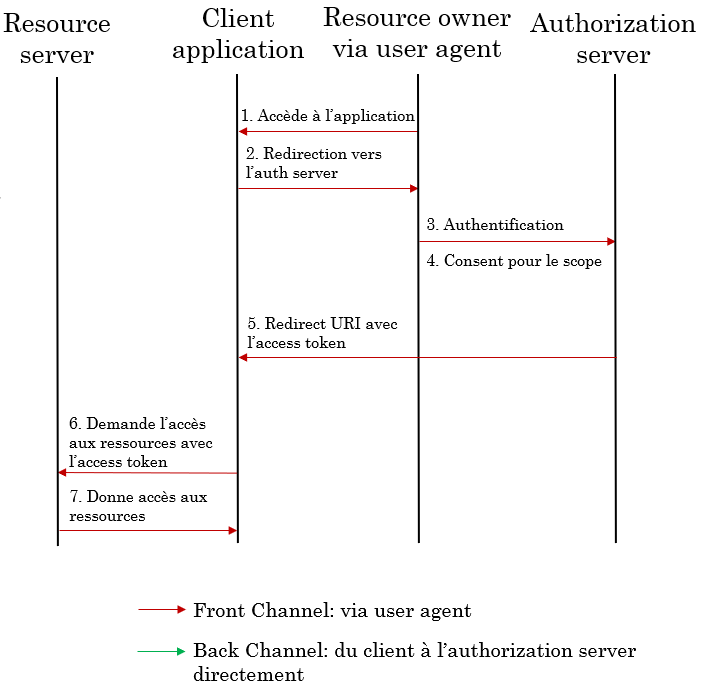
- L’utilisateur accède à l’application Client qui veut avoir accès à des ressources de l’utilisateur (contacts Facebook, channels Slack, repos GitHub)
- Le Client redirige vers l’auth server en demandant le scope approprié, et demandant directement un access token
- L’utilisateur s’authentifie sur le server
- Il accepte de donner accès au Client pour le scope
- L’auth server redirige l’utilisateur vers la Redirect URI spécifiée par le Client avec l’access token
- Le Client demande l’accès aux ressources en présentant l’access token dans la demande
- Le resource server valide l’access token et donne accès au Client
2.2.2 – Les appels HTTP
- GET /oauth2/authorize
?response_type=token (demande directement un token plutôt qu’un code)
&client_id=$ClientID
&redirect_uri=https://client-app.com/oauth2/callback\ &scope=resource1
&state=random42
HTTP/1.1
Host: auth-server.com - HTTP/1.1 302 Found
Location: https://client-app.com/oauth2/callback\ ?access_token=2YotnFZFEjr1zCsicMWpAA…
&state=random42
&token_type=bearer
&expires_in=3600
2.3 – Authorization code flow with PKCE (Proof Key for Code Exchange)
C’est la même chose que l’authorization code flow, mais avec quelques étapes en plus pour vérifier l’identité de la Client application.

- L’utilisateur accède à l’application Client qui veut avoir accès à des ressources de l’utilisateur (contacts Facebook, channels Slack, repos GitHub)
- Le Client redirige vers l’auth server en demandant le scope approprié, et demandant un authorization code. Il génère un code_verifier et il inclut dans la requête un code_challenge.
- L’utilisateur s’authentifie sur le server
- Il accepte de donner accès au Client pour le scope
- L’auth server enregistre le code_challenge, et redirige l’utilisateur vers la Redirect URI spécifiée par le Client avec un authorization code
- Le Client récupère le code et demande à l’échanger contre un access token. Il inclut le code_verifier.
- L’auth server vérifie le code_challenge avec le code_verifier. Le Client reçoit le JWT access token avec les claims sur le resource server
- Le Client demande l’accès aux ressources en présentant l’access token dans la demande
- Le resource server valide l’access token et donne accès au Client
2.4 – Client credentials flow
Ce flow est simple, il est fait pour les autorisations de serveur à serveur. Il n’y a pas d’utilisateur ici. Le resource owner est la Client application elle-même.
La Client application veut accéder à ses propres ressources.

- Le Client demande un access token en présentant ses client_id et client_secret
- Le Client reçoit le JWT access token avec les claims sur le resource server
- Le Client demande l’accès aux ressources en présentant l’access token dans la demande
- Le resource server valide l’access token et donne accès au Client
2.5 – Resource owner password credentials flow
Dans ce flow, l’utilisateur donne son password à la Client application, exactement ce qu’on ne voulait pas faire en utilisant oAuth2. Vous comprenez bien que ce flow n’est pas recommandé.
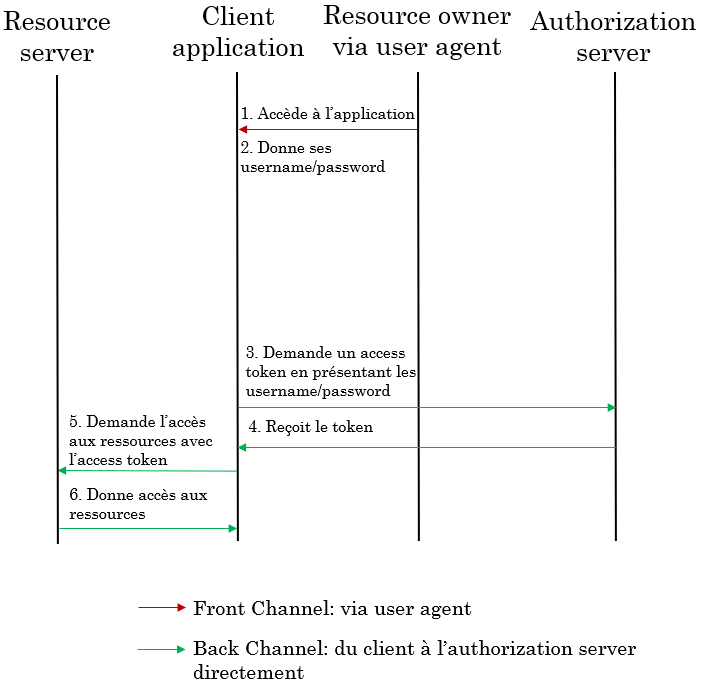
- L’utilisateur accède à l’application Client qui veut avoir accès à des ressources de l’utilisateur (contacts Facebook, channels Slack, repos GitHub)
- L’utilisateur donne ses username/password
- Il accepte de donner accès au Client pour le scope
- L’auth server redirige l’utilisateur vers la Redirect URI spécifiée par le Client avec un authorization code
- Le Client demande un access token en présentant les username/password de l’utilisateur
- Le Client reçoit le JWT access token avec les claims sur le resource server
- Le Client demande l’accès aux ressources en présentant l’access token dans la demande
- Le resource server valide l’access token et donne accès au Client aux ressources
3 – OpenID Connect
3.1 – De oAuth2 à OpenID Connect
Tous les flows que nous avons vus jusqu’ici ont servi à déléguer les autorisations de l’utilisateur à la Client application. Mais nous n’avons toujours pas authentifié l’utilisateur auprès de l’application. Tout ce que sait l’application, c’est que l’utilisateur en question a les droits sur les ressources auxquelles elle veut accéder. L’application ne sait pas qui il est.
Dans le cadre du SSO, nous voulons authentifier l’utilisateur auprès de l’application. Nous voulons donc que l’application accède aux informations sur l’identité de l’utilisateur. Ces informations sont des ressources qui appartiennent à l’utilisateur, auxquelles l’application peut donc demander l’accès via oAuth2.
oAuth2 a bien été utilisé pour faire de l’authentification mais chaque Identity Provider faisait ce qu’il voulait pour présenter les informations sur l’utilisateur (facebook, twitter, google, etc.)
OpenID Connect a été pensé pour normaliser la manière de récupérer les informations sur l’identité de l’utilisateur.
Ce n’est pas un nouveau protocol, c’est oAuth2 avec une couche de paramètres et endpoints normalisés, comme nous allons le voir.
Si nous voulons partir de la terminologie oAuth2 et rejoindre la terminologie SSO en parlant de Service Provider et d’Identity Provider, comment nous y prendre ?
La Client application est celle qui veut accéder aux informations sur l’identité de l’utilisateur, pour l’authentifier lorsqu’il y accède. Donc c’est la Client application qui fait office de Service Provider.
Le Resource server est celui qui a les informations sur l’identité de l’utilisateur, c’est donc lui qui fait office d’Identity Provider.
Et comme l’Authorization server est celui qui autorise l’accès à ces informations, il joue aussi le rôle d’Identity Provider.
Le Resource server et l’Authorization server sont la même entité.
Donc dans OpenID Connect, qui est une surcouche d’oAuth2, l’utilisateur qui veut accéder au Service Provider (la Client application), va s’authentifier auprès de l’Identity Provider (l’Authorization server et Resource server), qui va communiquer au Service Provider les informations sur l’identité de l’utilisateur.
OpenID Connect a sa propre terminologie que nous allons mettre ici, mais pour simplifier, nous allons continuer avec les termes Service Provider et Identity Provider.
- Resource owner (terminologie oAuth2) 🡪 Utilisateur à authentifier 🡪 End user (terminologie OpenID)
- Client Application (terminologie oAuth2) 🡪 Service Provider 🡪 Relying party (terminologie OpenID)
- Authorization server (terminologie oAuth2) 🡪 Identity Provider 🡪 OpenID provider (terminologie OpenID)
- Resource server (terminologie oAuth2) 🡪 Identity Provider 🡪 OpenID provider (terminologie OpenID)
3.2 – Authorization Code Flow pour OpenID Connect
Ici nous allons présenter le flow OpenID Connect qui se base sur l’Authorization Code Flow d’oAuth2.

- L’utilisateur accède au Service Provider qui lui demande de s’authentifier
- Le Service Provider redirige vers l’Identity Provider en demandant le scope “openid”, et demandant un authorization code
- L’utilisateur s’authentifie sur l’identity provider
- Il accepte de donner accès au scope “openid” et d’autres si demandés (profile, email)
- L’Identity provider redirige l’utilisateur vers la Redirect URI spécifiée par le Service Provider avec un authorization code
- Le Service Provider récupère le code et demande à l’échanger contre un access token et un ID token
- Le Service Provider reçoit le JWT access token et ID token avec les claims qui correspondent au scope (name, email, picture)
- Le Service Provider peut demander plus d’informations sur l’utilisateur en consultant le endpoint standard /userinfo en présentant l’access token dans la demande
- Le Service Provider valide l’access token et donne accès à l’utilisateur
OpenID Connect utilise donc oAuth2, même que c’est de l’oAuth2, mais en ajoutant certaines briques normalisées, comme l’ID token qui contient les informations de base sur l’identité de l’utilisateur, les scopes (name, email, picture), les claims (Standard Claims) et les endpoints.
OpenID Connect normalise les endpoints d’accès aux informations:
- Discovery endpoint : https://
/.well-known/openid-configuration qui contient des informations sur les autres endpoints de l’Identity provider (/authorize, /token) - UserInfo endpoint : contient des informations supplémentaires sur l’utilisateur
- jwks_uri endpoint : contient les clés publiques JSON Web Key Set qui ont servi à signer les tokens
3.2 – SSO avec OpenID Connect
Comme nous avions fait pour SAML dans le premier article, nous pouvons répondre aux questions que nous nous étions posés sur le SSO :
- Comment le SP connaît l’IdP ? L’IdP a un discovery endpoint qui contient toutes les informations
- Comment l’IdP connaît le SP ? En enregistrant l’application sur le service SSO de l’IdP, ou sur une plateforme SSO. Permet d’obtenir le client_id et client_secret.
- Comment le SP connaît les champs remontés par l’IdP ? Normalisés par OpenID Connect.
- Par où passe les tokens ? Par le backchannel dans le cas d’un auth code flow, ou par le navigateur dans le cas d’un implicit flow.
- Quelles informations ils contiennent ? Ceux normalisés par OpenID Connect (name, email, picture, etc.)
- Comment le Service Provider vérifie les tokens ? Grâce aux JSON Web Key Set qui est accessible via le discovery endpoint.
4 – SAML vs. OpenID Connect
4.1 – Comparaison des objets, des termes et du fonctionnemen

XML est plus lourd que JWT.
SAML passe par le browser pour envoyer l’assertion (moins sécurisé). Pour OpenIDConnect (auth code flow), il y a un back channel.
Pas d’échange de metadata avec OpenID Connect contrairement à SAML. Les endpoints et les claims sont normalisés.
Pour des SPA (Single Page Applications) et des NA (applications mobiles), ils ne peuvent pas signer le SAML AuthnRequest et donc ne peuvent pas facilement utiliser SAML. OpenID Connect leur permet d’utiliser PKCE pour s’authentifier. Et il y a le client_secret dans le back channel qui permet d’authentifier les Service providers auprès de l’Identity provider.
SAML nécessite un POST de l’assertion, et ce n’est pas évident avec des SPA ou des NA. Alors qu’avec OpenID Connect, ils reçoivent l’ID token en réponse.
4.2 – Entre SAML et OpenID Connect, que choisir ?
Clairement, la comparaison précédente avait pour but de montrer qu’OpenID Connect est une implémentation plus intéressante et plus portée vers le futur dans le cadre du SSO. Comme nous avions vu à la fin de premier article, SAML fonctionne très bien dans le cadre d’une authentification d’entreprise, mais :
Si vous avez de nouvelles applications à développer ou si vous voulez implémenter de l’authentification SSO pour la première fois, il vaut mieux miser sur OpenID Connect
Mais si vous utilisez SAML dans l’entreprise avec votre IdP, comment faire ? C’est là où les plateformes SSO peuvent être utiles : le service provider parle OpenID Connect avec la plateforme SSO (Okta par exemple), qui parle SAML avec votre Identity Provider.
4.3 – Pour finir
J’espère que cette présentation sur oAuth2 et OpenID Connect vous a permis de mieux comprendre ces protocoles qui sont très complexes mais très utiles et très complets.
Merci pour la lecture !


